
Niemal w każdej sekundzie dnia korzystamy z danych albo wytwarzamy ich kolejne zbiory: przeglądając strony internetowe, robiąc zakupy online, czytając serwisy informacyjne, korzystając z komunikatorów, czy z nawigacji. Takie zebrane dane mogą mieć nieocenioną wartość – ale tylko, jeśli zostaną odpowiednio przetworzone. Co to dokładnie oznacza, jakie są etapy procesu korzyści przetwarzania danych? Właśnie te zagadnienie omówimy w artykule.
Przetwarzanie danych, czyli Data Processing – co to dokładnie oznacza?
Przetwarzanie danych obejmuje metody zbierania surowych, oryginalnych danych i przekształcanie ich w użyteczne informacje.
Cykl przetwarzania danych
Proces przetwarzania danych wejściowych (oryginalnych i jeszcze niezmienionych) składa się z kilku kroków – kluczowa jest tu ich kolejność, aby przetworzone dane stały się wartościowym źródłem informacji.
Proces przetwarzania danych może być powtarzany – dane wyjściowe z jednego cyklu mogą być przechowywane i wykorzystane jako dane wejściowe do kolejnego. Dlatego też mówimy o cyklu przetwarzania danych.
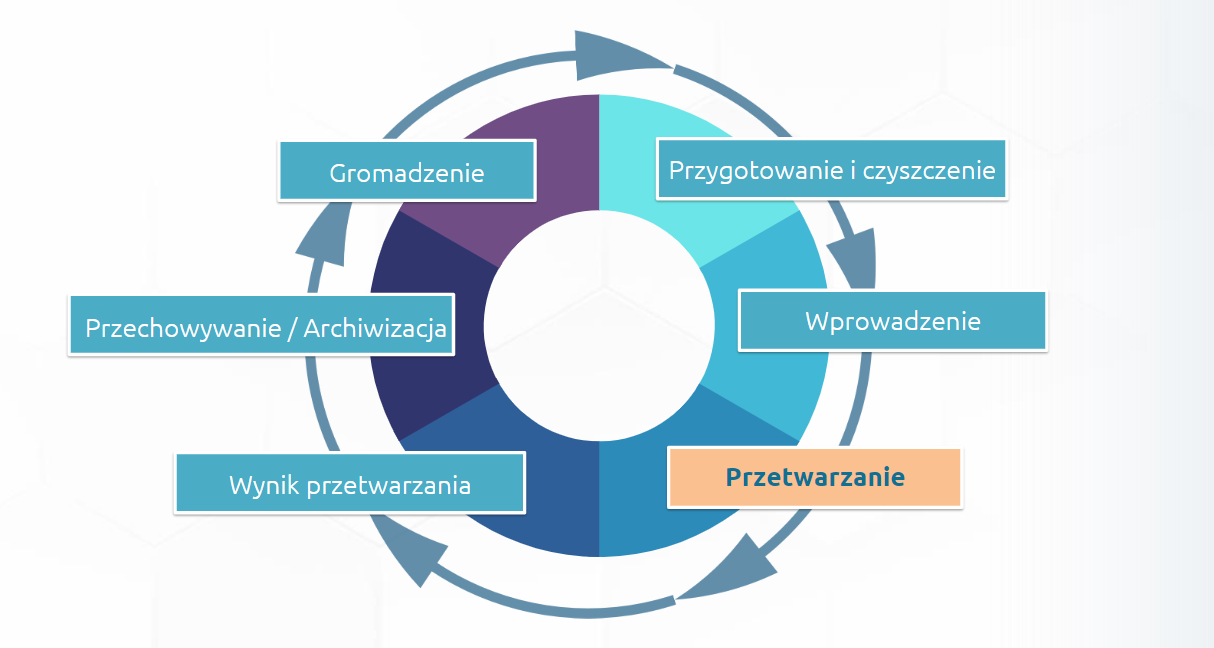
Omówmy po krótce kolejne kroki cyklu:
1. Zbieranie surowych danych
Na tym etapie trzeba pamiętać, że źródła, które chcemy wykorzystać muszą być sprawdzone i wiarygodne. W myśl zasady „trash in, trash out” nie uzyskamy dobrych wyników przetwarzania, jeśli dane wejściowe będą złej jakości.
2. Przygotowanie i czyszczenie danych
Polega na sortowaniu i filtrowaniu oryginalnych danych w celu usunięcia tych, które są zbędne lub niedokładne. Na tym etapie powinniśmy sprawdzić czy surowe dane nie zawierają błędów, duplikatów, nieprawidłowych wartości i czy są kompletne. Powinniśmy też upewnić się, że są w formacie, który pozwala na ich dalszą analizę i przetwarzanie (więcej na ten temat przeczytasz w artykule Błędy danych – jakie konsekwencje ma korzystanie z danych złej jakości?).
3. Wprowadzanie danych
W tym kroku, surowe, ale już wstępnie przygotowane i oczyszczane dane są przekształcane do postaci, która jest czytelna i zrozumiała przez aplikację lub maszynę zajmującą się dalszym i docelowym przetwarzaniem. Proces zaczytywania danych może mieć różną formę, np. ręczne wprowadzenie danych, zaczytanie pliku w konkretnym formacie czy zeskanowanie dokumentu.
4. Przetwarzanie danych
Na tym etapie dane poddawane są różnym metodom i technikom przetwarzania w celu otrzymania pożądanego wyniku. To, jak dokładnie przebiega ten etap jest w dużej mierze zależne od źródła, z jakiego dane zostały pozyskane oraz od celu w jakim są przetwarzane.
5. Wynik przetwarzania danych
Przetworzone dane są prezentowane użytkownikowi w czytelnej, przystępnej i użytecznej dla niego formie – w postaci wykresów, tabel, plików wektorowych, rastrowych, czy raportów. Dane w takiej formie mogą być dalej interpretowane, a także przechowywane i wykorzystywane w kolejnych cyklach przetwarzania danych.
6. Przechowywanie danych i ich archiwizacja
Ostatni etap, to przechowywanie i archiwizacja zarówno surowych danych wejściowych, jak i wyników przetwarzania, wraz z wszelkimi metadanymi. Prawidłowe przechowywanie danych pozwala na szybki i sprawny dostęp do nich i daje możliwość ich dalszego wykorzystania.
Narzędzia i technologie przydatne w przetwarzaniu danych
Przy obecnej ilości wytwarzanych danych, przetwarzanie ich ręcznie jest w zasadzie niemożliwe, dlatego stosuje się różne narzędzia, które automatyzują, przyspieszają i ułatwiają cały proces. Do najbardziej popularnych zaliczamy wykorzystywanie różnych języków programowania, języka SQL, a także użycie narzędzi Business Intelligence lub ETL a także platform integracyjnych. Każda z tych metod ma swoje mocne i słabe strony. Przyjrzyjmy się im po krótce.
Narzędzia Business Intelligence do analizy biznesowej
Przyjazny interface, predefiniowane modele analityczne, szerokie możliwości w zakresie prezentacji wyników to czynniki, które sprawiają, że narzędzia BI niezmiennie cieszą się ogromną popularnością. Szczególnie ceniona jest tu prostota i przejrzystość wizualizacji skomplikowanych analiz oraz dużych zbiorów danych kadrze kierowniczej czy klientom, którzy na ich podstawie łatwiej mogą podjąć świadome decyzje.

W swojej wyjściowej wersji narzędzia klasy BI mają jednak stosunkowo małą liczbę dostępnych połączeń do źródeł danych potrzebnych do przeprowadzenia analiz. Możliwości przygotowania danych pod dalsze analizy również są dość ograniczone. Z tego powodu częstą praktyką jest korzystanie z połączonych mocy narzędzi klasy BI i rozwiązań klasy ETL / ESB.
Narzędzia i oprogramowanie do analizy statystycznej
Narzędzia te umożliwiają tworzenie bardzo precyzyjnych analiz, np. analiz korespondencji, analiz rzetelności i pozycji, analiz skupień. Często są jedynymi, które są w stanie dostarczyć analiz o takiej dokładności i poziomie złożoności, jakich wymaga firma czy instytucja np. z sektora medycznego czy badań laboratoryjnych. Nie ma dla nich alternatywy. Ich beneficjentami, są zazwyczaj specjaliści dziedzinowi. W przeciwieństwie do systemów BI, wykorzystywanych przede wszystkim przez odbiorców biznesowych i kadrę kierowniczą wyższego szczebla.
Wadą rozwiązań do analizy statystycznej mogą być ich wysokie koszty – zarówno zakupu i późniejszego utrzymania. Wynika to z faktu, że tego typu narzędzia są często podzielone na kilka modułów – każdy z nich generuje dodatkowe koszty.
Różnego rodzaju języki programowania

Wykorzystanie różnych języków programowania to cały czas jedno z bardziej popularnych podejść. Oprócz niewątpliwej zalety jaką jest tworzenie skomplikowanych kodów na potrzeby zaawansowanych modeli uczenia maszynowego, techniki programistyczne są stosunkowo mało elastyczne, w porównaniu z innymi metodami. Szczególnie wtedy, gdy do początkowych założeń trzeba szybko wprowadzić zmiany wynikające np. z dynamicznie zmieniających się warunków biznesowych.
Ta metoda me też swoje wady zupełnie niezwiązane z samą analizą danych. Odpowiednio wykwalifikowani specjaliści zajmujący się przetwarzaniem danych (oprócz znajomości języków programowania) powinni posiadać również zaawansowaną wiedzę na temat procesów biznesowych – aby właściwie interpretować wyniki analiz lub tworzyć ich nowe scenariusze. Utrzymanie tak wysoko wykwalifikowanego zespołu może okazać się nie lada wyzwaniem.
SQL
Konsole SQL, wykorzystujące zapytania w tym właśnie języku programowania są bardzo dobrym sposobem na uruchamianie wielu scenariuszy analitycznych i uzyskanie precyzyjnych informacji zwrotnych.
Jednak wspominane zapytania przyniosą zadawalające rezultaty tylko, gdy dane będą odpowiednio ustrukturyzowane (wraz z zachowaniem relacji pomiędzy nimi).
W miarę rozrastania się bazy lub baz danych zachowanie takiego porządku może okazać się trudne dla administratorów – tak samo jak zarządzanie dostępami do źródeł danych.

Narzędzia ETL i platformy do integracji danych
Choć narzędzia integracyjne nie są systemami w zamyśle stworzonymi do prezentowania wyników, czy do wykonywania naprawdę skomplikowanych obliczeń lub analiz, coraz więcej firm decyduje się na włączenie ich do procesu przetwarzania danych.
Głównym zadaniem tego typu rozwiązań jest tworzenie połączeń pomiędzy systemami lub bazami danych, wysyłanie komunikatów, weryfikacja poprawności i kompletności danych oraz ich transformacja z zachowaniem istotnych atrybutów oraz schematu. Wszystko po to, aby zmaksymalizować ich przydatność na poczet dalszych analiz.
Platformy do integracji danych
Mogą być obsługiwane przez właścicieli biznesowych procesu, którzy nie są wykwalifikowanymi specjalistami przetwarzania danych.
Dzięki otwartości technologicznej oraz wbudowanej obsłudze licznych formatów danych mogą one wspierać osoby pracujące w różnych branżach i na różnych stanowiskach
Platformy integracyjne oszczędzają czas i pieniądze
Dużą zaletą platform do integracji danych jest to, że bazują na modelu no-code/low-code, dzięki czemu z powodzeniem mogą być obsługiwane przez właścicieli biznesowych procesu, którzy nie są wykwalifikowanymi specjalistami przetwarzania danych. Możliwości tych narzędzi można rozszerzyć poprzez dodatkowe skrypty w języku programowania Python czy R. Użytkownicy, po uzyskaniu niezbędnych kompetencji, mogą z powodzeniem, samodzielnie rozbudowywać środowisko rozwiązań, ograniczając w znacznym stopniu zjawisko tzw. vendor lock, czyli uzależnienia od dostawcy oprogramowania, z którego korzystamy.
Dzięki otwartości technologicznej oraz wbudowanej obsłudze licznych formatów danych (również tych mniej popularnych) mogą one wspierać osoby pracujące w różnych branżach i na różnych stanowiskach. Przy wykorzystaniu Platform Integracyjnych możemy przetwarzać dane tabelaryczne, wektorowe, rastrowe, bazy i hurtownie danych, usługi sieciowe typu WMS, WFS, różnego rodzaje API czy informacje pozyskane z czujników IoT.
Platformy integracyjne oferują też szerokie możliwości automatyzacji zaprojektowanych procesów. Dzięki temu oszczędzamy czas i pieniądze, a kompetencje pracowników, którzy zajmują się danymi mogą być wykorzystane w innych obszarach.
Decydując się na narzędzia klasy ETL lub Platformy Integracyjne, trzeba dobrze przeanalizować cele do jakich będą wykorzystywane, aby nie ponosić zbędnych kosztów. Są to złożone rozwiązania, które oferują niemal nieskończone możliwości – które być może zostaną zupełnie niewykorzystane, jeśli okaże się, że na potrzeby danej organizacji wystarczyłyby o wiele prostsze narzędzia.
Jakie korzyści niesie ze sobą data processing – czyli po co właściwie to robimy?
Jak wspomnieliśmy na początku, zbierane dane – bez przetworzenia i analizy w konkretnym celu, są w zasadzie bezużyteczne. Za to odpowiednio przygotowane dają wymierne korzyści biznesowe. Przetwarzania danych to krok milowy w stronę:
W analizie danych mogą nam pomóc odpowiednio dobrane mechanizmy sztucznej inteligencji. Dzięki temu proces ten będzie jeszcze szybszy.
Jednym z popularnych narzędzi do przetwarzania danych jest Platforma FME. Aby dowiedzieć się jak może ułatwić Ci przetwarzanie danych i dalszą pracę z nimi wejdź na stronę rozwiązania.