
Czas na kolejną porcję informacji o zwiększaniu wydajności FME. Temu tematowi poświęciliśmy ostatnie webinarium „Najlepsze techniki i optymalizacja pracy w FME” (nagranie dostępne tutaj). W poprzedniej części artykułu opisaliśmy wpływ hardware’u oraz systemu operacyjnego na szybkość działania FME i wydajność przetwarzania danych. Zapraszamy do lektury kolejnej części!
Czasami nie można zmienić parametrów systemowych maszyny, na której zainstalowane jest FME. Warto zatem skorzystać ze wskazówek i porad, jak zwiększyć wydajność narzędzia podczas budowania skryptów.
Lepsza wydajność podczas tworzenia obszarów roboczych
Cache’owanie obiektów (tzw. Feature Caching)
Jedną z dobrych praktyk podczas tworzenia skryptów w FME jest wprowadzanie niewielkich zmian i częste uruchamianie obszaru roboczego. Dzięki temu stopniowo sprawdzasz wyniki poszczególnych etapów skryptów. Metoda pozwala na szybsze zlokalizowanie błędów niż wtedy, kiedy sprawdzamy wiele transformatorów. Częste uruchamianie obszaru roboczego może być stosunkowo czasochłonnym procesem, ale można go nieco skrócić, korzystając z opcji Feature Caching.
Uruchamianie procesów z tą funkcją pozwala na przechowywanie wyników obszaru roboczego po każdym etapie tłumaczenia. Dzięki temu można sprawdzić wyniki po każdym etapie. Ponadto po uruchomieniu przetwarzania nie trzeba uruchamiać całego obszaru roboczego, ponieważ można wykorzystać tymczasowe wyniki, zapisane w pamięci podręcznej. Metoda ta zużywa miejsce na dysku i dostępne zasoby podczas zapisywania pamięci podręcznej, ale pozwala na oszczędność czasu przy ponownym uruchomieniu obszaru roboczego.
Wskazówka: Jeżeli obszar roboczy jest kompletny i wprowadzany do środowiska produkcyjnego, należy pamiętać, by wyłączyć opcję Feature Caching. Gdy funkcja pozostanie włączona, może uniemożliwić działanie narzędzi wydajnościowych, tj. przetwarzanie równoległe. W środowisku produkcyjnym tworzy też rzadko używane pamięci podręczne. Poza tym obszar roboczy w produkcji nie powinien być uruchamiany w połowie. Dlatego też podczas uruchamiania obszaru roboczego na FME Server cache’owanie obiektów jest automatycznie wyłączane.
Licznik obiektów (tzw. Feature Counting)
Licznik obiektów to liczby, które pojawiają się na połączeniach pomiędzy poszczególnymi transformatorami podczas uruchamiania obszaru roboczego w FME Workbench. Zliczanie tych elementów w czasie rzeczywistym często wskazuje, które transformatory blokują dane lub spowalniają obszar roboczy.
Czyszczenie atrybutów
Podczas przetwarzania FME przechowuje dane w pamięci (fizycznej lub wirtualnej) lub dane są tymczasowo zapisywane na dysku. Wydajność transformacji możesz poprawić m.in. poprzez zmniejszenie ilości przechowywanych, niepotrzebnych danych. Dotyczy to zarówno obiektów, jak i ich elementów.
Wskazówka: Jednym z powodów, które mogą spowalniać przetwarzanie danych w FME, jest nadmiar atrybutów. Bardzo rzadko zdarza się, aby w procesie transformacji wykorzystywane były wszystkie atrybuty, zawierte w danych wejściowych. Warto więc jak najszybciej pozbyć się atrybutów, które są zbędne, np. używając odpowiednich transformerów.
Zarówno producenci FME, jak i doświadczeni użytkownicy, zalecają pracę według poniższego schematu:
- Wczytanie danych
- Usunięcie zbędnych atrybutów
- Dalsze przetwarzanie
Innymi słowy, w procesie transformacji powinny brać udział tylko te atrybuty i geometrie obiektów, które mają być dostępne w wyniku końcowym. Aby usunąć niewykorzystywane atrybuty, skorzystaj z takich transformerów jak AttributeManager, AtributeRemover czy Attribute Keeper. Dodatkowo transformer GeometryRemover pozwoli na usunięcie zbędnych geometrii obiektów.
Filtrowanie danych
Podobnie jak w przypadku zbędnych atrybutów, nadmiarowe obiekty w zbiorze danych również mogą wykorzystywać cenne zasoby systemowe. Usuń je na jak najwcześniejszym etapie przetwarzania danych.
Zalecany schemat pracy jest niemalże identyczny jak w przypadku czyszczenia atrybutów:
- Wczytanie danych
- Filtrowanie danych
- Dalsze przetwarzanie
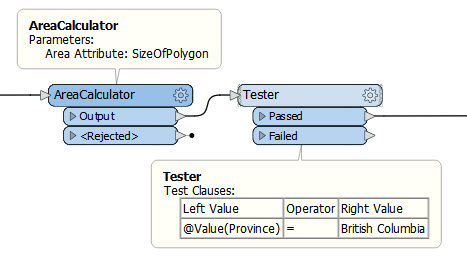
Poniżej zaprezentowaliśmy błędny sposób pracy w FME, w sytuacji, gdy autor chciał pracować tylko z częścią swoich danych wejściowych.
Celem tego skryptu było wyznaczenie powierzchni poligonów znajdujących się w prowincji Kolumbia Brytyjska w Kanadzie. Aby proces przebiegł szybciej, autor w pierwszym kroku powinien za pomocą funkcji Tester odfiltrować tylko te poligony, które znajdują się na zdefiniowanym obszarze zainteresowania. Dopiero później powinien obliczyć ich powierzchnie. A na powyższym zdjęciu widać, że w pierwszej kolejności wyznaczono powierzchnię dla wszystkich obszarów, a dopiero w kolejnym kroku przefiltrowane do obszaru zainteresowania – co znacząco spowalnia przetwarzanie danych.
Duplikowanie transformatorów
Bardzo częstym błędem jest tworzenie procesów, które składają się z kilku identycznych transformatorów, występujących po sobie (tzw. łańcuch zduplikowanych transformatorów). Taka praca zazwyczaj jest mniej wydajna niż przetwarzanie całości w jednym transformatorze.
Przykładem tego błędu może być użycie kilku transformatorów ExpressionEvaluator w taki sposób, że każdy z nich wykonuje inny krok jednego większego obliczenia. Znacznie lepszym rozwiązaniem będzie skondensowanie wszystkich tych działań w jeden transformer np. AttributeManager, który zawiera w sobie te same funkcjonalności co ExpressionEvaluator.
Grupowe przetwarzanie obiektów
FME przekazuje obiekty do przetwarzania na wiele różnych sposobów. Niektóre transformatory przekształcają naraz tylko jeden obiekt, a inne pracują na grupach obiektów. Wówczas są to transformery, które przetwarzają wiele obiektów jednocześnie, np. w procesie przycinania wielu obiektów liniowych w celu utworzenia sieci topologicznej.
Transformery działające na grupie obiektów muszą przechowywać je wszystkie w swojej pamięci tymczasowej, co wiąże się z wyższymi kosztami przetwarzania. Im więcej obiektów w danej grupie, tym zużycie zasobów i koszt przetwarzania wyższy. Proces ten możesz zredukować poprzez ustawienie odpowiednich parametrów transformera. Przykładem może być DuplicateFilter, który filtruje elementy zduplikowane według wybranego atrybutu. Funkcja ta będzie działała lepiej, jeśli dane dla transformera posortujesz według kolejności kluczy. Musisz wtedy ustawić jeden z parametrów transformera na Input is Ordered by Group.
Wskazówka: Podczas tworzenia procesu oraz wyboru transformatorów zapoznaj się z ich dokumentacją. Dowiesz się dzięki temu, czy transformator jest oparty na grupie obiektów i czy tym samym zwiększy się koszt przetwarzania. Jeśli korzystasz z transformatorów przetwarzających grupy obiektów, zajrzyj do dokumentacji, by dowiedzieć się, jakie ustawienia parametrów zmniejszą koszty ich pracy, np. tryb grupowania.
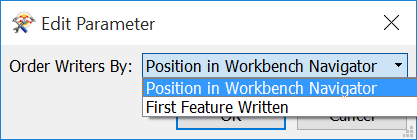
Kolejność writerów ma znaczenie
Kiedy w skrypcie występuje kilka funkcji zapisujących, mają one ustaloną kolejność wykonywania. Jako pierwsze zapisują się dane kierowane do Writera, który jest pierwszy w oknie nawigatora wśród wszystkich Writerów w skrypcie. Pozostałe funkcje zapisujące przechowują w pamięci podręcznej przetworzone dane. Czekają w ten sposób, póki nie nadejdzie ich kolej. Kolejność writerów możesz dowolnie zmieniać w oknie Navigator.
Korzystanie z zaawansowanych ustawień przestrzeni roboczej – Order Writers By, pozwala określić kolejność zapisu danych (np. według kolejności w Navigatorze lub według kolejności dotarcia obiektów do poszczególnych Writerów).
Wskazówka: Jeśli w skrypcie FME występuje więcej niż jedna funkcja zapisująca, ich kolejność ustaw tak, by jako pierwsze zapisywane były dane, których jest najwięcej. Nie będzie wtedy konieczności przechowywania dużych zbiorów w pamięci podręcznej, co spowolniłoby Twój proces przetwarzania danych.
Praca z bazami danych
Czytanie danych oraz ich zapis do baz danych pozwala poprawić wydajność przetwarzania na wiele sposobów. Zdarza się, że wstępne przetwarzanie w bazie może być szybsze niż przy pomocy FME. Dlatego najlepszym i najczęściej zalecanym podejściem jest filtrowanie danych już na etapie ich odczytu z bazy danych. Możesz sprawdzić dwa scenariusze:
Filtrowanie danych możesz wykonać przy użyciu zapytań SQL lub klauzuli SQL WHERE. Są one dostępne w większości readerów umożliwiających czytanie z baz danych.
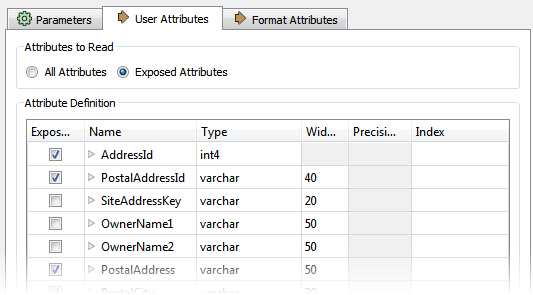
Innym sposobem filtrowania jest unikanie odczytywania zbędnych atrybutów z tabeli bazy danych. Można je wyłączyć w parametrach Readera, w zakładce User Attributes:
Scenariusz 1:
- Filtrowanie danych w bazie danych
- Odczyt danych przy pomocy FME
- Dalsze przetwarzanie danych
Scenariusz 2:
- Odczyt danych przy pomocy FME wraz z filtrowaniem obiektów
- Dalsze przetwarzanie danych
Filtrowanie danych możesz wykonać przy użyciu zapytań SQL lub klauzuli SQL WHERE. Są one dostępne w większości readerów umożliwiających czytanie z baz danych.
Innym sposobem filtrowania jest unikanie odczytywania zbędnych atrybutów z tabeli bazy danych. Można je wyłączyć w parametrach Readera, w zakładce User Attributes:
W przypadku łączenia danych z różnych baz sprawniej i szybciej niż tradycyjny transformator FeatureJoiner zadziała zapytanie SQL Joins.
Maksymalne wykorzystanie zasobów systemowych
Nieco dziwna może wydawać się sugestia wykorzystania jak największej ilości zasobów systemowych. Jest to jednak dopuszczalne, a czasami nawet zalecane – o ile wykonujesz tę akcję prawidłowo. Jeśli pracujesz na komputerze z ośmiordzeniowym procesorem, zasadne wydaje się podzielenie pracy na 8 części, tak aby każdy rdzeń mógł mieć swój udział.
Podczas przetwarzania danych przy pomocy FME Server warto mieć do dyspozycji kilka silników obliczeniowych. Zaleca się wtedy posiadanie jednego silnika na każdy rdzeń, chociaż może się to różnić w zależności od typu i rozmiaru przetwarzanych danych.
Jeśli chodzi o pamięć, dobrze byłoby odczytać całą zawartość tabeli z bazy danych w jednym zapytaniu – niezależnie od tego, czy wymagane są wszystkie obiekty z bazy, czy nie. Czytanie pojedynczych rekordów na żądanie, chociaż wiąże się z mniejszym ruchem w sieci, może być wolniejsze.
Dzielenie i równoważenie danych
Przetwarzanie bardzo dużej ilości danych w ramach jednego zadania może być skomplikowane. Warto rozważyć podzielenie całego zbioru danych na grupy (np. na podstawie regionu geograficznego) i przetwarzanie każdej z nich oddzielnie.
W przypadku przetwarzania danych dla całej Polski, można podzielić je na grupy odpowiadające jednemu województwu. Taki podział można wykonać, używając klauzuli Where. W ten sposób dane zostaną podzielone na szesnaście różnych grup, a każda grupa będzie przetwarzana po kolei w zależności od liczby silników FME.
Aktualizacje i ulepszenia w kolejnych wersjach FME
Platforma FME jest stale rozwijana i ulepszana – w ciągu roku wychodzą aż 3 oficjalne wersje programu. Wraz z każdym nowym wydaniem poprawiana jest również wydajność narzędzia. Można wyróżnić dwa rodzaje ulepszeń wydajności FME:
- Automatyczna, czyli taka, która jest stosowana do silnika FME podczas każdej aktualizacji platformy do nowszej wersji. Ulepszenia te są kompatybilne wstecz i zmieniają jedynie wydajność skryptu, a nie sposób jego działania.
- Uprzednio zaplanowana aktualizacja jest inicjowana przez użytkownika FME. Ulepszenia te są dostępne po wprowadzeniu nowej wersji platformy, ale nie są implementowane automatycznie. Mogą, ale nie muszą być one kompatybilne wstecz, dlatego bardzo istotne jest, by wiedzieć, jakie różnice w działaniu skryptu mogą nastąpić po ich wprowadzeniu.
Aby samodzielnie wprowadzić te aktualizacje, które nie są wgrywane automatycznie, w FME Workbench przejdź do okna Navigator i w sekcji Transformers znajdź te transformatory, które możesz zaktualizować.
Ponieważ są to opcjonalne ulepszenia transformatora, zawsze przed ich wprowadzeniem sprawdź, jakie modyfikacje zostaną wprowadzone i czy nie spowodują one zmian w działaniu funkcji.
Jeśli dziennik zmian danego transformatora zawiera poniższą informację:
Added support for Bulk Mode
…wówczas po jego aktualizacji możesz spodziewać się poprawy wydajności. Dzieje się tak np. w przypadku transformatora StatisticCalculator, którego działanie zostało znacząco usprawnione w FME 2020.

W FME 2020 StatisticsCalculator był średnio o 88% szybszy niż w poprzednich wersjach platformy, a niektóre działania można było wykonać nawet 100 razy szybciej! W FME 2021, którego premiera nastąpi już w marcu 2021, kolejne transformery zostaną znacząco przyśpieszone.
Ale jak możesz zauważyć – w oknie Navigator – istnieje wiele innych transformatorów, które są aktualizowane i zawsze warto je sprawdzić, by upewnić się, czy nie będą one negatywnie wpływać na oczekiwane wyniki działania skryptu.
Warto również wspomnieć, że poprawa wydajności jednego transformatora może pozytywnie (ale też negatywnie) wpłynąć na wydajność reszty obszaru roboczego.
Podsumowanie
Nie ma złotego środka na lepszą wydajność pracy z FME. W zależności od skryptu czy rodzaju wykorzystywanych danych możesz stosować różne sposoby opisane w naszym artykule. W niektórych przypadkach wystarczy wprowadzić jedną lub dwie omówione wskazówki. W innym przypadku dopiero instalacja na mocniejszym sprzęcie i kilka zaleceń związanych z pracą w FME i budowaniem skryptów sprawi, że zauważysz widoczną poprawę wydajności działania platformy.
Artykuł na podstawie materiałów oraz dokumentacji Safe Software.